
Edge computing has been on the technology scene for more than three years and is still a vaguely defined term. Just as in the early days of cloud computing, this is due to the fact that various manufacturers are/ were rebranding a business-as-usual IT product or service with the fashionable term. In the early days of cloud computing, we analysts called it “cloud washing”. Today we are seeing almost the same thing happening again with the edge computing providers. However, CIOs should not fool themselves. Just as not every enterprise data center will become a private cloud, not every locally distributed computer or IoT device will become an edge computing topology. This expert view is therefore essential not only for the providers of the new class of computing, but also for CIOs who really want to understand and take advantage of the benefits without falling for the marketing of global and local providers. The Expert View is the first in a small series of three articles, which are accompanied by a free webinar.
Unfortunately, the industry has not agreed on any definition at all or only on a very general one. This is what happens when every manufacturer wants to see his technology in this term:
Edge computing is any type of computing, storage or network performance that is very close to a user or machine and far away from consolidated data centers. (Edge computing definition Wikipedia)
According to this, every PC that is located on a workstation and not in a data center would be an edge computing device. However, Cloudflight sees both the device in the network topology and the computing paradigm as characteristics of edge computing.
Edge Computing is a computing approach in which computing, storage, or network power is made available in the same way at many decentralized locations of a larger network topology. It can act partially autonomously but is managed centrally. (Edge computing definition Cloudflight)
This definition makes it clear that not every remote PC or Internet gateway on an industrial machine can be understood/ defined as edge computing. In detail, we speak of Edge Computing when these characteristics are given:
- Edge topology: A single computer or embedded device is not an edge computing device until it is on the edge of a larger network topology. It does not matter whether an edge device communicates directly with a public or private cloud or the next larger edge device – or even with all of them simultaneously. It just has to have connectivity . Even if only sporadically, data sharing and real-time interaction is one of the two most important tasks of an edge computing approach.
- Edge computing, storage or network services: Besides communicating with the rest of the network topology, local autonomy is the second important feature of edge computing. A robot controller must locally detect humans and, if necessary, slow down movements to prevent accidents, but at the same time it must be integrated into a larger Industry 4.0 network. A traffic light control system at a major city intersection must be 100% reliable and consistent to avoid local traffic chaos, but at the same time – if possible – communicate with surrounding traffic lights or a traffic control center to reduce congestion and emissions.
- Edge-device class: Although edge computing can include a very wide range of devices, we only talk about edge computing if there is at least one non-constrained controller, which for example already has a file system in which customer-specific programs or data are stored. At the upper end, there may well be powerful computers such as those needed today in autonomous vehicles or automated factory halls. As long as these are themselves an “external” part of a central topology, one can very well speak of edge computing. However, classic enterprise computing servers, which are loaded very individually with business software, are on-premises in classic data centers precisely because they are not supposed to communicate to an even more central node (outside the company). We therefore clearly no longer refer to these compute resources as edge computing.
- Standardised deployment and management on the edge: A single virtual machine or container is far from being a cloud computing platform. Only a high degree of standardization, automation and ultimately the flexible pay-per-use billing model create a public or private cloud. Similarly, it is the same with edge computing: Decentrally distributed computing power is far from being an edge computing approach. This is why we do not refer to traditional SCADA systems (Supervisory Control and Data Acquisition), for example, as they are used at countless industrial plants, as edge computing. Their software is usually delivered once when the physical plant is commissioned and is hardly ever, let alone automatically, updated centrally afterwards. Each machine can have a different software status. In addition, the classic SCADA systems do not speak to other parts of a network topology, mainly for safety reasons. In practice, a SCADA system is then often supplemented with a small local Internet gateway, which has exactly the opposite properties of the SCADA itself, i.e. it is highly standardized, is remotely managed and can pass on sensor data. We therefore refer to such retrofit gateways as edge computing devices.
As a result, the definition of edge computing depends not only on the size and characteristics of a device, but on the larger concept in which these devices operate. Let us compare it to Client/ Server Computing: Here, not every PC automatically became a client of a Client/ Server topology. Many PCs were simply slightly better typewriters and operated completely locally. Only those PCs loaded with identical or at least compatible client software could operate with the server software in the data centre.
If one were to compare edge and client/ server computing with nature, it would probably be a tree with many leaves and root ends. While the leaves are visible to humans, like clients today, or powerful browser applications like Google’s GSuite, the roots symbolize many invisible edge computing devices, from the tip of the root, through small and medium-sized nodes, to the trunk of the tree that brings the two parts together in a corporate network. Let us take a closer look at the different classes of edge computing devices and their usual place in the topology: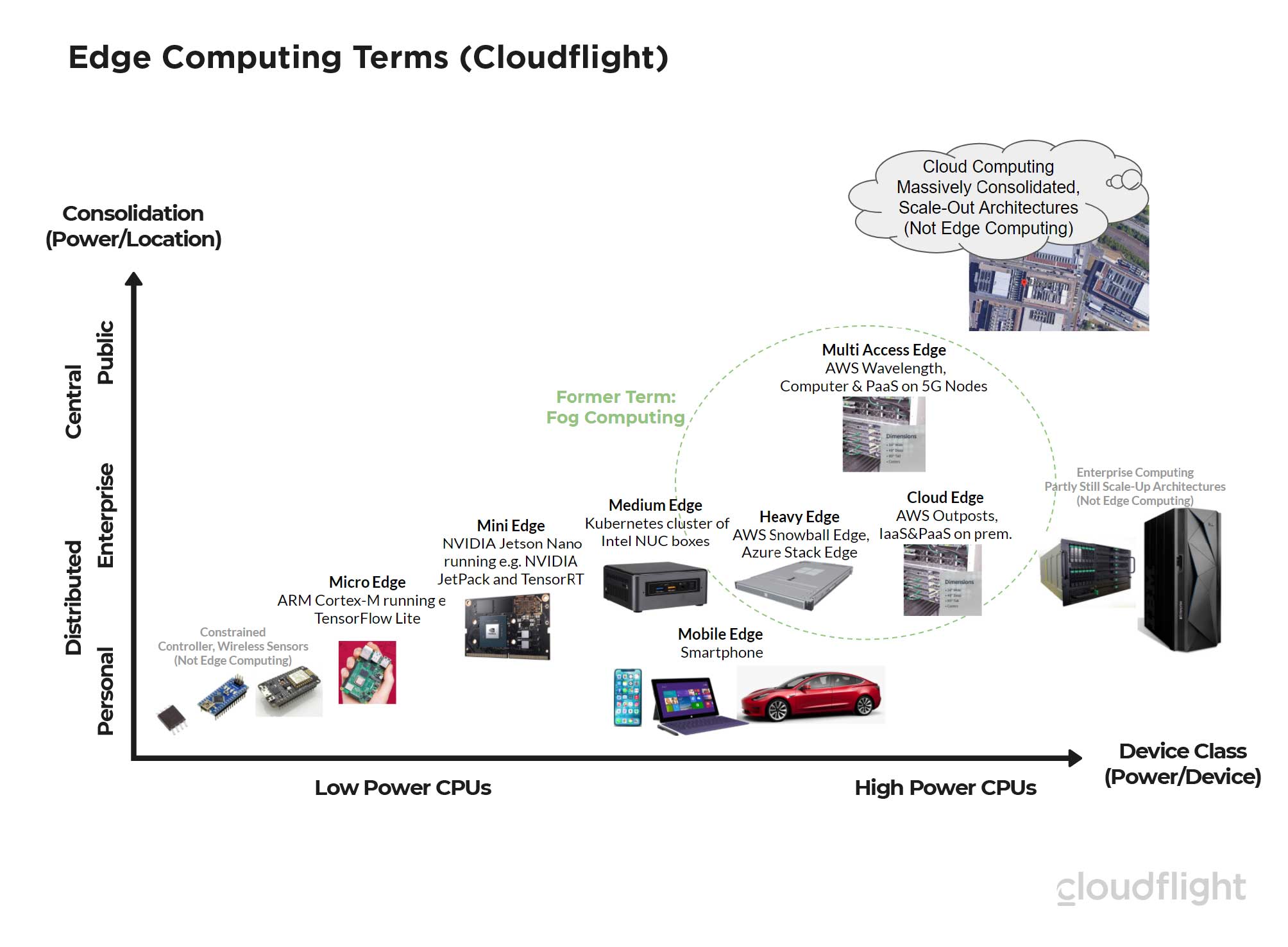 The picture shows the central consolidation at the top and the decentralized distribution of devices close to people or machines and far away from a central data center infrastructure. The performance classes are plotted from left to right. The following groups are shown in detail:
The picture shows the central consolidation at the top and the decentralized distribution of devices close to people or machines and far away from a central data center infrastructure. The performance classes are plotted from left to right. The following groups are shown in detail:
- Constrained controller – not yet edge computing: On the far left there are small microcontrollers in the milliwatt to approx. 1 Watt power class. The smaller representatives, for example with an ATMEL ATTINY or an Espressif EPS32 controller, can be found today in light switches, smoke detectors with standby currents of about 1µA. A battery therefore lasts 5 years or longer. The somewhat larger constrained controllers can already take over local tasks autonomously, for example in vehicles. However, because there is neither a real file system nor sufficient computing, storage or network power, these small controllers are not yet called edge computing devices.
- Micro Edge – the small Linux devices: In this performance class between half and four watts per controller, you can already represent a hardened Linux system and have hardly any classical limitations (constraints) of the small microcontrollers. The Raspberry Pi, popular for prototypes, is also located here. Commercial manufacturers such as Wago or INSYS icom now also offer the possibility of deploying customer-specific software as docker containers on their mini industrial computers for installation in control cabinets. This provides an extremely stable and also very flexible system. Machine learning frameworks such as TensorFlow Lite are already running here.
- Mini Edge – more power for special applications: Special edge-machine learning devices such as the NVIDIA Jetson Nano running the much more powerful Nvidia TensorRT are one example of this category. These devices are slightly higher in terms of the required power but can still be extremely distributed. Machine learning applications in particular only make sense here if local autonomy is continuously linked to a learning process in the cloud. This means that personal or confidential data is local but the greater artificial intelligence is created on a large pool of anonymized data in the cloud.
- Medium Edge – the industrial PCs or Kubernetes nodes: Here we are talking about 5 to 25 Watt power consumption per device. Logically, these devices are already too big to be built into a light switch. Usually they consolidate a whole production machine or a whole floor or even a whole building in building services engineering. Here it is already possible to decentralize considerably larger computing tasks. The management of containers with Kubernetes is particularly interesting. The medium edge devices appear just like a compute node in the cloud. So it makes no difference whether a container lands in the edge all by itself or together with 20 other containers on a virtual machine, which are located in a data centre together with 10,000 other VMs.
- Heavy Edge – distributed servers for special tasks: There are now computer systems for practically every performance class. If, for example, data in the range of terabytes per day or more accumulates at a production plant, it makes little sense to transport all this to a cloud or even to a corporate data centre outside the production location for reasons of latency and cost. In many cases, this data is only needed for a certain period of time for compliance reasons or can be deleted after it has been processed by learning and analytics algorithms. This is where heavy edge systems help, which usually only fill parts of a rack, but are offered by enterprise infrastructure providers as well as public cloud providers (e.g. AWS Snowball Edge, Azure Stack Edge). The heavy edges are usually limited to individual tasks such as data storage and are only partially integrated into the management systems of the public clouds.
- Cloud Edge – a piece of public cloud within the company: For years, public cloud providers were only able to provide services in the cloud. But the need for hybrid approaches has now been addressed by all three hyperscalers (AWS, Google, Microsoft) with corresponding cloud edge offers. A decisive factor in characterizing a cloud edge is that these are not just infrastructure services (IaaS), but that the provider also offers large parts of its platform software services (PaaS) as a fully-managed service on hardware at the customer’s premises. Examples are Microsoft’s Azure Stack, which represents local hardware with its partner companies, and Amazon’s AWS Outposts, which represents it with its own hardware. For a more detailed analysis of the Hyperscaler’s cloud edge offerings, please read this Expert View. In the meantime, there are also local cloud providers in Germany, who offer cloud edge solutions that include platform software for the manufacturing industry in addition to local data centres. Oncite is an example behind the German Edge Cloud (in which the Innovocloud has also been merged) as well as the companies IOTOS and BOSCH. In particular, the use of the Gaia-X framework on a cloud edge and in parallel on several public clouds is very promising for industry 4.0 scenarios (see the Gaia-X Cloudflight analysis).
- Mobile Edge – not every car can be considered edge computing: In terms of performance, of course, from left to right in the illustration, the mobile devices from smartphones and laptops to modern cars are lined up. They are very close to the users and thus potentially very far away in the topology to central infrastructures. If we again apply the above criteria for edge computing, only those vehicles can be described as edge computing devices, for example, which are in regular exchange with a central infrastructure in terms of data and locally executed programs. Typically, these modern vehicles then communicate with a digital twin through which other processes or mobile apps interact with the vehicle. A traditional vehicle that is not part of a larger network topology is not what we would call edge computing, similar to traditional SCADA systems at industrial plants.
- Multi Access Edge – computing power in 5G nodes: While the cloud edge is really in a single company and only used by that company, exactly the same approach can be applied to the “telco edge”. By this, telecommunications providers mean locations that are very far out on the way to transmitters and not in consolidated data centres. In this case the infrastructure is of course shared by many customers. These approaches are particularly attractive for software providers in the SaaS model. While central application parts, for example from AWS, are operated in the public cloud, latency-critical parts, such as video relay software, can be provided directly in the “vicinity” of the users. If the Multi Access Edge comes from the same provider (AWS Wavelength), it can be provisioned from the same Cloud Management System. Technically, the Multi Access Edges simply appear as additional availability zones. If this provisioning also happens automatically, it is called Network Function Virtualisation (NFV) on the edge.
- Enterprise and cloud computing – both central approaches: Cloud data centres are now in the range of 100 megawatts for individual availability zones. They are thus much more consolidated than most large enterprise data centres. Nevertheless, the cloud infrastructure follows a scale-out approach that fits well with cloud-native architectures. Here, there is a large number of the same primarily medium-sized server units. In contrast, there is still a lot of enterprise software, which, as the size of the company grows, ranges from ever larger servers to large SAP Hana shared memory appliances or mainframes. So the mainframe is even further to the right in the figure than the public cloud data centre, but this is much more consolidated and therefore the highest up.
Despite the long list, the market is still on the move. It is foreseeable that new edge categories will appear or others will disappear. Some manufacturers also spoke of Fog-Computing at the powerful Edge Computing Groups in companies and at the Telco-Edge. However, the term is hardly used in Europe today.
As mentioned above, software architecture and network topology is an important feature of edge computing. The sum of infrastructure, topology and software architecture is what we call the computing concept or paradigm. To make it easy for CIOs to identify edge computing opportunities, we have compared the characteristics of the four common computing paradigms: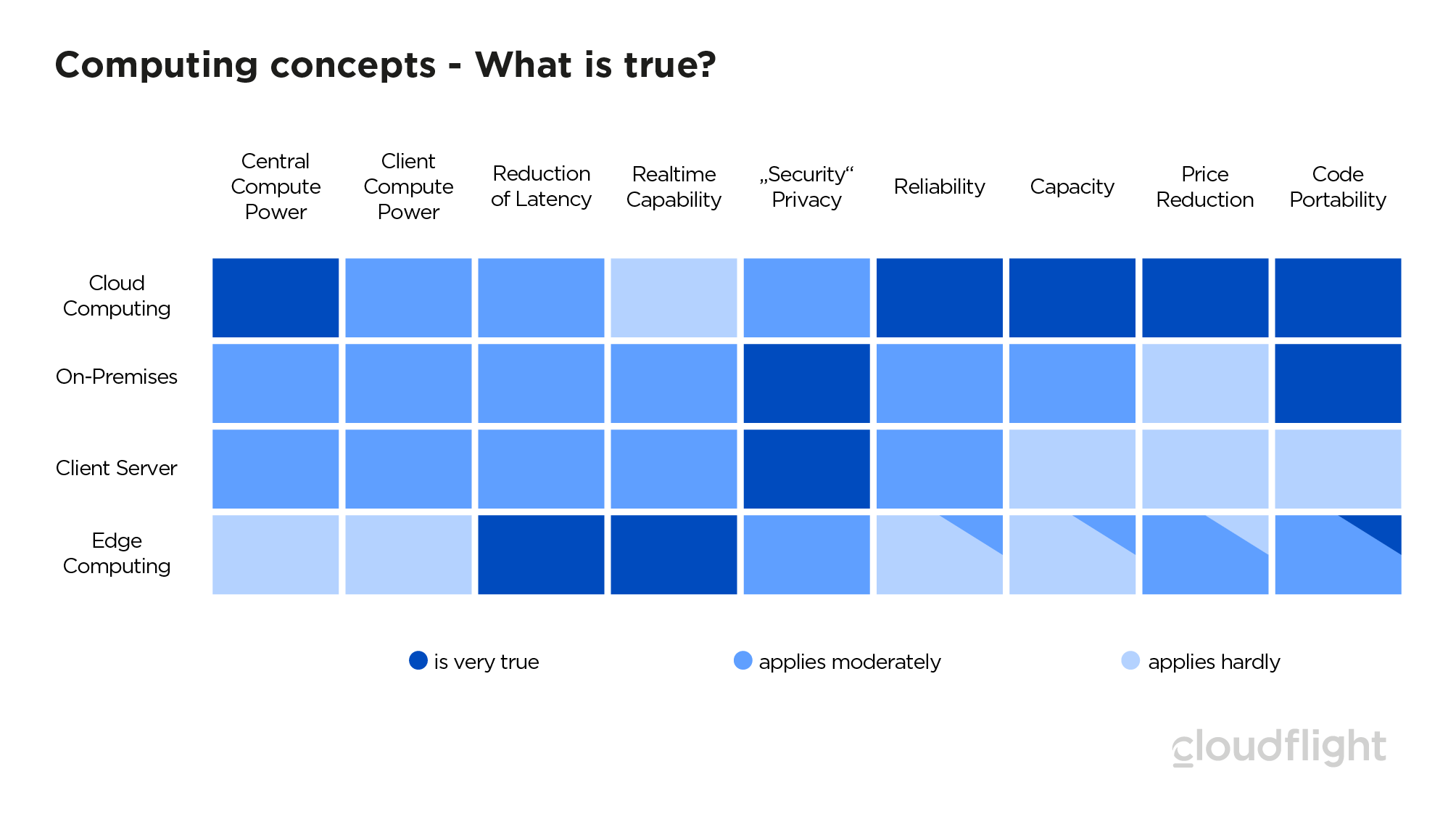 In the figure, nine characteristics of computing paradigms are considered and colour coded to show how strongly or weakly they apply. A complete discussion of the nine times four, i.e. 36 characteristics would certainly go beyond the scope of this expert view. We will therefore limit ourselves to a few examples or the remarkable characteristics:
In the figure, nine characteristics of computing paradigms are considered and colour coded to show how strongly or weakly they apply. A complete discussion of the nine times four, i.e. 36 characteristics would certainly go beyond the scope of this expert view. We will therefore limit ourselves to a few examples or the remarkable characteristics:
- Central processing power is hardly necessary with edge computing. The edge itself is autonomous when on the move. In order to operate an edge topology, no centralized power is required as in the client-server approach. The demands on the central management systems are low. Nevertheless, many software architectures – especially around machine learning – combine the edge, which generally gets by with mostly economical computers, with cloud computing, which provides high performance at a central location.
- Minimal latency is a great advantage of edge computing. Even the fastest network connections of an industrial production into a public cloud today have a latency of 10 to 20 milliseconds. The locally placed edge can control robots in the microsecond range, for example.
- The bigger the edge, the more available it usually is. Public clouds are – if used correctly – very highly available at a few points of the software stack due to redundant availability zones and persistent business data. In addition, Kubernets and Terraform help to realize multi-cloud deployments. This means that applications can be created in minutes at another provider, if an entire public cloud provider really does fail nationwide. These multi-cloud strategies currently achieve the highest availability (see column reliability). The Cloud Edge and also many Heavy Edge achieve at least a medium availability like classic Enterprise Computing On-Premises. The smaller edge classes, however, are individual devices that usually do not have a highly available power or network supply. This means that individual edge devices alone have poor reliability.
- Code portability – An old dream becomes reality. Ever since operating systems have existed, people have been dreaming of running code written on one system on other computers. The combination of container technology and the Intel architecture, which is standardized over a wide range, makes it possible to run exactly the same containers from the medium edge to the public cloud. If you go to the code level that can be executed by multiple families of processors, such as AWS with Greengrass on the Edge and Lambda in the Cloud, you can actually run the same code from the 4 Watt Raspberry to the 100 Megawatt data centre without any changes. For the Mobile Edge this is usually not possible in practice.
Ultimately, it is the software architecture that makes the edge computing topology an edge computing paradigm that differs in all areas from existing computing paradigms. This enables CIOs to distinguish marketing promises from facts and to plan for edge computing as a realistic contribution to tomorrow’s infrastructure. From a strategic point of view, you should take the following with you for your infrastructure planning:
Edge Computing Guidelines 2021:
- Edge Computing is a new computing paradigm.
- Edge and Cloud Computing coexist most of the time and hardly ever compete.
- Design a centralized management of the distributed infrastructure.
- Edge computing makes many industry 4.0 applications possible through low latency.
- An IoT device alone is not considered edge computing. You need to plan the network topology.
- Edge Computing is only interoperable with Cloud and Enterprise Computing through standards.
- Infrastructure and software architecture belong closely together in the cloud-native age. Have interdisciplinary teams within your company.
These guidelines will hopefully help you to plan your infrastructure and budget for a successful 2021.


