
Some avoidable mistakes that make AI projects fail
In this blog article some case studies where AI was applied incorrectly are analyzed. The intention is to raise awareness for this topic.
In the past few years, AI slowly made its way into our lives. Often we don’t even realize that we or our decisions are supported by an AI, for example when we type text in our smartphone, a search on the internet or see online advertisements. This can be quite convenient in our everyday life but what if there are similar systems that make decisions about us? A system that decides if you qualify for a loan? A system that supports court decisions? When it comes to public institutions and classifying people, those systems may affect our lives more than we are aware of and than we can influence.
To better understand why this might be a problem, one has to understand how data driven AI models are learning. As implied, they learn from data. That means that they can only learn what we show to them. At this point it is important to keep in mind that the data is very often produced by humans and already contains human bias and are therefore not as clinical as we might think.
In this blog article some case studies of non-optimal AI usage are analyzed. The intention is not to blame anyone, but to raise awareness for this topic, as the impacts are often underestimated.
The myth of self optimizing systems
AI software is often advertised as the ultimate missing puzzle piece that can magically solve all your problems by simply “continuously learning from data and optimizing itself”. Unfortunately there is not (yet) that one AI that can solve all problems and model optimization in the live system does not always take the direction that was intended.
One famous example of what can go wrong with continuous learning of a model in the live system is Tay Tweets.
Tay Tweets is a chatbot that was released on twitter and steadily learns from interacting with people. Everyone could mention the bot and it would learn from what people write and answer them. So it happened that – after only a few hours after its release – it turned into a racist, women hating bot and denied historical facts and was therefore taken offline. This happened despite the company that developed the bot implemented some safety nets to avoid such incidents. By telling the bot what it should think and a lot of repetitions the bot still learned unintended information.
It is close to impossible to automatically track how the model in the live system develops, especially when language is one of the main components.
Why we don’t do learning in live system
We don’t see any additional value in continuously updating the models in the live system. Therefore we train a model and perform an extensive evaluation on an external testset, so that we know how well a model will perform on future data. The process is visualized in figure 1. This model is then put in production and – if necessary – retrained in a later point in time with more data. This way we can avoid unexpected behavior to suddenly appear and also have model versioning.
The importance of correct interpretation of results
The methodically correct evaluation of models and interpretation of the results is a crucial step in the development of AI software to get a clear picture of how the model will perform on future data. If the output of an optimization is interpreted and used in a wrong way, it can even influence and harm the life of humans.
Recently the public employment service in Austria ordered a company to implement a system that rates the chances of a person on the job market. The chances are classified into high chances to find and keep a job, medium chances and low chances. The most focus will be put on people with medium chances as they claim that people with high chances will easily find a new job by themselves. A set of features was created and a positive or negative value is assigned to each feature based on past data. A few features that are used and their assigned score are shown in Figure 2. Based on those features, a “score” for your chances on the job market is calculated. Amongst other features, for example “gender”, “age” or “citizenship” are included which means that everyone has either an advantage or a drawback just by features that can not be influenced by themselves. And so it happened that for example women and non-EU citizens are automatically ranked lower.
Apparently the system has a classification rate of 80%-85% which means that around 50.000 people are incorrectly classified every year! The system is now in the testphase and will be re-evaluated after that phase and an external evaluation of the algorithm is ordered.Calculation starts at 0.1
- -0.14 – female
- -0.7 – age > 50
- +0.16 – EU citizen
- -0.05 – non EU citizen
- -0.15 – caretaker (“Betreuungspflichtig”)
- -0.18 to -0.82 – Region where you live
- +0.65 to +1.98 – depending on how fast a job was found in the past
- Competence activity
- Participate 1 time: -0.57
- Participate 2 times: -0.21
- Participate 3 times: -0.43
- And many more…
Fig 2: An excerpt of features that are used for calculating the score.
How to avoid that bias is implemented into a computer based decision system?
A big portion of time has to be invested to make sure that all kinds of bias are removed from the dataset. This includes personal information, for example gender, age, country, etc. Most likely the classification rate will drop when those features are removed and that is completely fine. It just means that an automated classification is not possible with the provided features. Knowing this is preferred over having software that systematically discriminates against certain groups of people.
Unfortunately, many similar cases exist in different contexts:
The impact of false positives
Another pitfall in evaluations of AI Systems is automatically connecting low percentages for wrong classification with actual low numbers.
At one train station in Berlin a face recognition test was conducted with the goal to detect criminals. They conducted two test phases. In the first one, high quality reference images were applied, in the second one the images were taken from a video stream. First of all, no concept for diversity in the people that took part in the test phases was defined, though they claim to have a representative set of participants.
The results of the test phases are shown in Figure 3. Overall the results of “Testphase 2” were better than “Testphase 1”. A higher accuracy and lower false acceptance rate was achieved. In the final report they claim that the results – considering the surrounding conditions and influencing factors – can be viewed as excellent.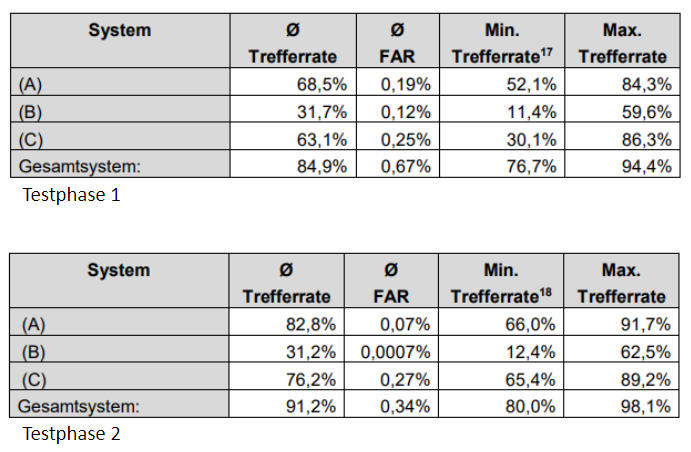
Again, Germany is not the only country that tests the use of face recognition software in public space to find criminals. It is already quite common in China and even Austria has started first tests.
Lessons Learned
Avoiding bias in AI-Systems is a task that includes far more attention than usually expected and calculated in estimations. One also has to take into account the impact of this bias. For tasks that include i.e. data about machines it might not be as big as for tasks that include data about humans.
Some steps of how to tackle bias:
- Know your data. How was it created? Under which circumstances? Is it a good basis for AI tasks? It is important to understand the data and possible bias in your data. When we have a first look into data, we perform an explorative data analysis to get a good overview.
- AI is not able to solve all problems at once. We always discuss the business case with our customers to get the best value out of the AI solution. We first identify quick wins and scale/extend them later on.
- AI does not solve problems at 100% perfection. However, humans conduct errors as well. So it makes sense to also evaluate human behavior when judging an AI system.
- Use AI only if it’s adequate. Many problems can be solved better without AI.
- AI systems in many cases contain a degree of human error that was implemented via the data that was used for training.
- Remember that AI is not evil.
- Make sure that the dataset is as diverse as possible
- Create a testset with cases that showed bias in the past to test the model after a retraining
The austrian government has recently released their government program for the next five years . One point is the definition of a “red line” in AI applications in the public sector. For example, AI is not allowed to take over decisions that have an immediate impact on humans – only support the decision. This is a first step in the right direction to avoid institutionalized discrimination, but still the applications have to be double and triple checked to make sure that this is not happening.
Sources
http://www.forschungsnetzwerk.at/downloadpub/arbeitsmarktchancen_methode_%20dokumentation.pdf
https://www.derstandard.at/story/2000089720308/leseanleitung-zum-ams-algorithmus
https://futurezone.at/meinung/der-beipackzettel-zum-ams-algorithmus/400641347
https://www.dieneuevolkspartei.at/Download/Regierungsprogramm_2020.pdf