
This expert view is the second report in a series around one of the most important design elements of modern IoT architectures – the digital twin. We’ve already explored the basic definition of digital twins in our first report and derived recommendations to Chief Digital Officers. As a brief recap, there are basically two types of digital twins: The Digital-Twin-Prototype (DTP) which describes a product to be built, and the digital twin Instance (DTI) which give access to the product along the full post-production lifecycle:

The full product lifecycle including manufacturing
We’ve touched already in the previous report the wide variety of data types and corresponding enterprise systems related to a digital twin. This may span from PLM systems connected to a Digital-Twin-Prototype down to autonomous driving machine learning systems connected via the digital twin Instance to a physical vehicle. With the current expert view, we want to focus on the question that we hear frequently from enterprise and IoT-architects: Which data should be stored in the twin?
To investigate a crisp answer of the question, we want towant remind our readers of the original purpose of a digital twin. It is an IoT architecture element which enables a software program talking to a physical product – no matter if the product is actually online or not – or in the case of an Twin-Prototype, if the physical product does exist already or not! Here are some examples to illustrate the challenge:
- DTP Example: An CNC manufacturing machine or robot may ask a “part” in the manufacturing process to tell its customer specific variation. So the digital twin is most likely not responsible to manage and transfer the basic CAD/CAM (computer aided design/manufacturing) data to the robot. The robots may get these instructions as a one-time configuration of the manufacturing line. However, the digital twin should hold the customer specific variation. This might be only a few bytes of deviation from the mass production, or even a complex configuration in the example of consumer vehicles built to individual orders.
- DTI Example: A B2B vehicle like a cargo truck has a GPS receiver connected to enable the fleet manager tracing the actual position and calculating for example the estimated delivery time. Ideally, the truck does not connect directly into fleet management systems but sends its GPS data simply to its digital twin. Then the fleet management systems can access the (last known) GPS position of the truck (even if the vehicle is currently offline). In this example, the twin makes obviously the coding of the fleet management system much easier. It does not have to deal with any IoT communication and can rely on always available GPS data. However, do you expect the twin to store all precise GPS traces of every vehicle to a long time, e.g. for audit and insurance purposes? Some architects may build a full time series of GPS tracking right into the digital instance twin. We at Cloudflight believe constantly growing time series or telematic data might be better stored in a dedicated data lake, while the twin acts simply as a proxy to access or retrieve these historic sources.
Let’s focus on the digital twin instance for the following top level discussion of the data architecture. Like with many technology terms, there is also the tendency to pack everything and anything into the new term and turn it into the secret sauce solving any IoT challenge. This is actually a design challenge and could lead to very complex and unmanageable digital twins. To avoid this, we want to remind IoT architects on some best practices from many digital twin design sessions we’ve done with Cloudflight clients:
- Cover all actual states of the physical device. Any business application should have access to the state of the devices such as sensor data through the twin, if privacy allows this. None of the applications shall access the device directly. Even writing to variables to change the state of IoT devices should happen through writing a desired state to the digital twin.
- Implement all offline reading and writing functionality of the covered states. In addition to the above coverage of all actual states, bridging the offline gap is the second key capability of minimalistic instance twins. This shall always be considered in both directions: A business application may write into the twin, no matter if the device is online or not, and the device might write into the local digital twin API, no matter if it is online or not. Once the device is online again, both twins, the physical device and digital twin synchronize each other again.
- Keep application logic out of the digital twin. Application logic may be located in the surrounding business applications or meanwhile in more powerful edge devices. The twin itself may be the delivery mechanism distributing for example container files to the edge devices, but the digital twin itself should never be the execution environment for business logic. The only exception is the logic that is very generic to the twin itself. For example a smart optimistic locking dealing with concurrent writing access while the device is offline, should be part of the twin itself.
- Keep Process Logic out of the digital twin. As already mentioned in the previous report, the digital twin’s duty is not the execution of a process. Ideally, the twin is just an end-point to APIs. It shall notify other applications that fresh data is there via events, but it is not responsible for pushing certain data sets to consuming applications in the way a traditional middleware does.
- Establish a proxy to larger data volumes in the cloud. Some IoT architects actually store very large data sets in the digital twin natively and merge the twin and a data lake architecture. While this is possible, we believe it is not best practice. If you have really large volumes of telematic or other time series data, you might better leverage an appropriate off-the-shelf storage solution. The twin might automatically offload data there and could still offer a proxy to a query interface. This means, a developer would be able to ask always (the API of) the digital twin, but it answers natively only for the most current data and forwards the request for large volumes of past data.
- Establish a proxy to real-time data on the device. The digital twin concept of reading and writing to devices that may be occasionally offline, does not work for all applications. Sometimes, you need to be sure that the data is real real-time data. The non-autonomous remote control driving out of a garage or parking lot of Tesla car is such an example. Other examples are about data with privacy concerns that should not be stored in the OEM’s twin storage, but should be available to the owner of the car exclusively.
Let’s explore the unofficial Tesla API (www.teslaapi.io) which is the basis for all Smartphone apps, the official one by Tesla, as well as many third party apps. The API is a full abstraction of the access to all Tesla consumer equipment including cars and home batteries or solar panels. According to the above guidelines we can classify the data domains and explore their external exposure or assume their internal usage by Tesla. If enterprise and IoT architects like to design a digital twin data domain model, a distribution of all entities into these three classes and by two or more privacy levels is a smart approach.
These are the following three data domains:
- Real digital twin: This domain really implements the remote access and distribution of states as intended by the digital twin concept.
- Remote vehicle access: This is basically a proxy API directly to the online vehicle. Surprisingly, the majority of consumer APIs at Tesla and corresponding data sets fall into this category.
- Remote cloud access: This is a proxy API to a larger data volume stored in the cloud as recommended above.
The difference between real twin data and the remote vehicle access domain becomes very obvious in case of Tesla vehicles, as they can go into sleep mode after some hours out of use. While the basic information about a vehicle and its driving/sleeping state is always available, requesting data such as the the GPS location fails, if the vehicle sleeps. The application developer needs to call the wake-up API and then requests the GPS location again. Although it looks really inconvenient to developers, the obvious background locating this data in the “Remote Vehicle Access”domain is the European data privacy regulation. If the user does not bring his/her vehicle online, Tesla has no access to this private information. Even if the car is online as usual, Tesla never stores this information in relation to the vehicle or user identity.
The distribution of data across the domains looks like this:

Access methods and security domains of Tesla’s digital twin (Source: Cloudflight)
In addition to three access categories, we explore two privacy categories, consumer accessible and OEM confidential. The size of the above boxes indicate the number of APIs and data sets or commands in each combination. Looking at the consumer accessible APIs, which are documented on www.teslaapi.io, it is remarkable that most of the data is actually NOT mirrored in the digital twin. This is obviously a great message for many data security and privacy experts, but it means that many API calls need to wake up the full car remotely and could quickly cause a phantom power consumptions of more than 5 kWh per day while the car is parking. It is also interesting that Tesla decided NOT to disclose any cloud services about the car’s historic data. So, if you like to generate for example a full battery charging log, you need to use for instance a third party app or hook your Tesla API up to a smart home system, which can easily log all this data.
It is obvious that for example B2B vehicles such as commercial trucks, would distribute the data domains totally different. Once you have a trusted B2B relationship with the customer, as much current data as possible will be in the real twin to reduce bandwidth and latency of remote vehicle access. Additionally, commercial B2B vehicles might leverage historic data from the real digital twin and monetize this as a remote cloud access. Think of logistic routing optimization or similar use cases.
Unfortunately, Tesla does not disclose much about the non-public APIs and data domains on the left side of the above picture. Fortunately, it is straightforward to assume the OEM confidential part based on publicly visible or promoted features:
- Real digital twin & OEM confidential: All the Over-The-Air (OTA) update of software falls into this category. Tesla knows exactly which software version is in each of the 50+ embedded devices of every car – and they know this for sure without polling the cars.
- Remote vehicle access & OEM confidential: Tesla does “record” very few data by default. For indemnification reasons they record for example the autonomous driving level in case of an accident. Even if the car is totally damaged and out of power, they said a couple of times in public that certain cars did or did not use autonomous driving at the time of an accident. Tesla does record telematic data to improve the autonomous driving capabilities, if the user switch the data sharing on. Tesla might also have remote access to embedded devices for diagnosis purposes – but this might be different by regions.
- Real cloud access & OEM confidential: There are examples showing that certain vehicles get access to the data generated by others. The learning data of the autonomous systems is the obvious one. It is improved by the data contribution of everybody who switched the telematic data sharing on. Another example of this category is the recording of road bumps and potholes. Once a single car reports the vertical acceleration measured in the suspension system, the following Tesla Model S get a warning to reduce speed or increase the ground clearance automatically with its air suspension. Tesla claims officially that all this data is fully anonymized.
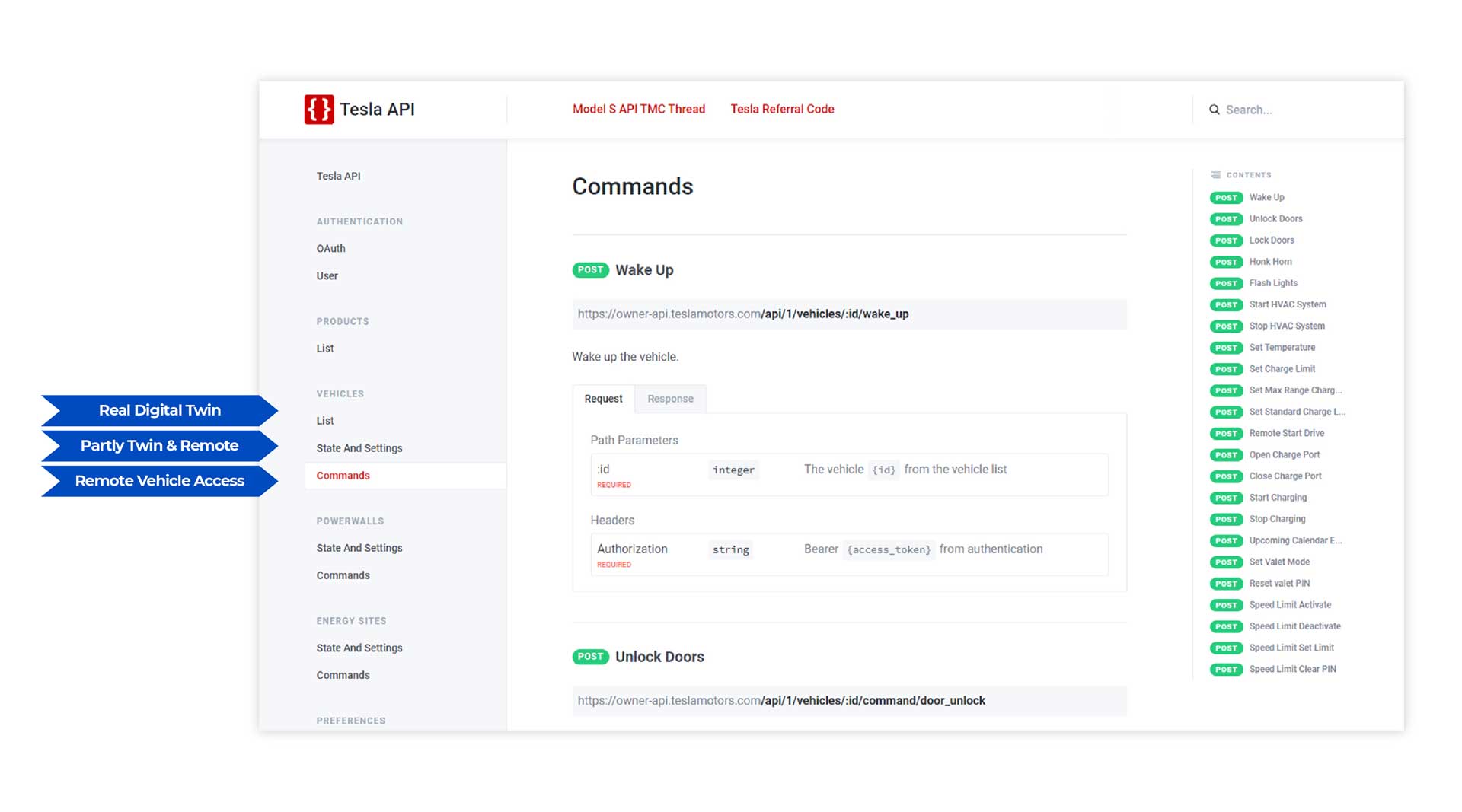
Tesla Digital Twin APIs: Source www.teslaapi.io
The picture shows the Tesla API documentation and how the three sections fall into our classification. Enterprise and IoT architects should browse these example and use the introduced digital twin data categories to structure their data models and access layers of their digital twin. The approach also helps to structure the implementation waves of your individual twin architecture in an agile way. Depending on the digital business model, you might start on the “OEM confidential” or on the “consumer accessible” side first.
Cloudflight is happy to share more successful digital twin examples on demand.



