
Dieser Expert View ist der zweite Teil im Rahmen einer Artikelserie über eines der wichtigsten Design-Elemente moderner IoT-Architekturen – dem digitalen Zwilling (Digital Twin). Wir sind bereits in unserem ersten Artikel auf die grundlegende Definition von Digital Twins eingegangen und haben daraus Empfehlungen für Chief Digital Officer abgeleitet. Kurz zusammengefasst gibt es grundsätzlich zwei Arten von Digital Twins: Der Digital-Twin-Prototyp (DTP), der ein zu entwickelndes Produkt beschreibt, und die Digital-Twin-Instanz (DTI), die den Zugriff auf das Produkt während des gesamten Lebenszyklus nach der Fertigstellung ermöglicht:

Der gesamte Produktlebenszyklus, einschließlich Fertigung.
Im vorangegangenen expert View haben wir bereits die große Vielfalt der Daten-Domainen und der entsprechenden Unternehmenssysteme im Zusammenhang mit einem Digital Twin thematisiert. Das Spektrum reicht von PLM-Systemen, die mit einem Digital-Twin-Prototypen (DTP) verbunden sind, bis hin zu Machine-Learning-Systemen für autonomes Fahren, die über die Digital-Twin-Instanz (DTI) mit einem physischen Fahrzeug verbunden sind. In der vorliegenden Expert Views liegt unser Schwerpunkt auf der Frage, die wir häufig von Enterprise- und IoT-Architekten hören: Welche Daten sollten im Digital Twin gespeichert werden?
Um eine knackige Antwort auf diese Frage zu erhalten, möchten wir unsere Leser an den ursprünglichen Zweck eines Digital Twin erinnern. Es handelt sich um ein IoT-Architektur-Element, mit dem ein Softwareprogramm mit einem physischen Produkt kommunizieren kann – unabhängig davon, ob das Produkt tatsächlich online ist oder nicht – oder im Falle eines Twin-Prototypen, ob das physische Produkt bereits vorhanden ist oder nicht! Die folgenden Beispiele veranschaulichen die Herausforderung:
- Beispiel DTP: Eine CNC-Fertigungsmaschine oder ein Roboter fordert einen „Teil“ im Fertigungsprozess auf, die kundenspezifische Varianten mitzuteilen. Daher ist der Digital Twin höchstwahrscheinlich nicht dafür verantwortlich, die grundlegenden CAD/CAM-Daten (Rechnergestützte Konstruktion/Fertigung) zu verwalten und an den Roboter weiterzugeben. Die Roboter erhalten diese Anweisungen üblicherweise in Form einer einmaligen Konfiguration der Fertigungslinie. Der Digital Twin sollte jedoch die kundenspezifische Variante enthalten. Dabei kann es sich um eine Abweichung von der Massenproduktion im Bereich weniger Bytes handeln oder sogar um eine komplexe Konfiguration im Falle von PKWs, die nach individuellen Kundenbestellungen gebaut werden.
- Beispiel DTI: An ein kommerzielles Fahrzeug wie bei einem Lkw ist ein GPS-Empfänger angeschlossen, mit dem der Fuhrparkmanager die Position verfolgen und beispielsweise die voraussichtliche Lieferzeit berechnen kann. Im Idealfall stellt der Lkw keine direkte Verbindung zu den Flottenmanagementsystemen her, sondern sendet seine GPS-Daten einfach an seinen Digital Twin. Dann können die Flottenmanagementsysteme auf die (letzte bekannte) GPS-Position des Lkw zugreifen (auch wenn das Fahrzeug derzeit offline ist). In diesem Beispiel erleichtert der Twin die Programmierung des Flottenmanagementsystems offensichtlich erheblich. Er kommt vollkommen ohne IoT-Kommunikation aus und kann sich auf ständig verfügbare GPS-Daten verlassen. Doch gehen Sie davon aus, dass der Zwilling alle präzisen GPS-Traces jedes Fahrzeugs über längere Zeiträume speichert, z.B. für Revisions- und Versicherungszwecke? Einige Architekten bauen vielleicht eine vollständige Time-Series des GPS-Tracking direkt in den Digital-Instanz-Twin ein. Wir bei Cloudflight sind der Meinung, dass ständig anwachsende Zeitreihen oder Telematikdaten besser in einem dedizierten Data Lake gespeichert werden sollten, während der Twin lediglich als Proxy fungiert, um auf diese historischen Datenquellen zuzugreifen oder diese abzurufen.
Lassen Sie uns für die folgende Top-Level-Diskussion über die Datenarchitektur den Schwerpunkt auf die Digital-Twin-Instanz legen. Wie bei vielen technologischen Begriffen gibt es auch hier die Tendenz, alles und jedes in den neuen Begriff hineinzupacken und ihn zu einem Allheilmittel für jede IoT-Herausforderung zu machen. Dies ist eine echte Design-Herausforderung und könnte zu äußerst komplexen und unkontrollierbaren Digital Twins führen. Um dies zu vermeiden, möchten wir IoT-Architekten an einige Best Practices aus zahlreichen Design-Sessions für Digital Twins erinnern, die wir mit Kunden von Cloudflight durchgeführt haben:
- Alle Ist-Zustände des physischen Geräts abdecken. Jede Unternehmensanwendung sollte über den Twin Zugriff auf den Gerätezustand wie z.B. Sensordaten haben, wenn die Datenschutzrichtlinien dies zulassen. Keine der Anwendungen sollte direkt auf das Gerät zugreifen. Sogar der Schreibvorgang auf Variablen zur Änderung des Zustands von IoT-Geräten sollte durch Schreiben eines gewünschten Zustands auf den Digital Twin erfolgen.
- Implementierung aller Offline-Lese- und Schreibfunktionen der abgedeckten Zustände. Neben der oben beschriebenen Erfassung aller Ist-Zustände stellt die Überbrückung des Offline-Gaps die zweite Schlüsselfunktion minimalistischer Instanz-Twins dar. Dies ist stets in beide Richtungen zu berücksichtigen: Eine Unternehmensanwendung erhält Schreibzugriff auf den Twin, unabhängig davon, ob das Gerät online ist oder nicht, während das Gerät Zugriff auf die lokale API des Digital Twin erhält, unabhängig davon, ob es online ist oder nicht. Sobald das Gerät wieder online ist, synchronisieren sich beide Twins – das physische Gerät und der Digital Twin – wieder miteinander.
- Anwendungslogik aus dem Digital Twin heraushalten. Anwendungslogik kann sowohl Teil der umgebenden Geschäftsanwendungen als auch von leistungsfähigeren Edge Devices sein. Der Twin selbst kann als Übergabemechanismus fungieren, der z.B. Containerdateien an die Edge Devices verteilt. Der Digital Twin selbst sollte hingegen niemals die Ausführungsumgebung für die Geschäftslogik sein. Nur sehr generische Logik für den Twin selbst stellt die einzige Ausnahme dar. Zum Beispiel sollte ein “Smart Optimistic Locking” Teil des digitalen Twins selbst sein, um konkurrierende Schreibzugriffe während der Offline-Zeit aufzulösen.
- Prozesslogik aus dem Digital Twin heraushalten. Wie bereits im vorhergehenden Artikel herausgestellt wurde, besteht die Aufgabe des Digital Twins nicht in der Durchführung eines Prozesses. Im Idealfall stellt der Twin nur einen Endpunkt für APIs dar. Er benachrichtigt andere Anwendungen in Form von Ereignissen über das Vorliegen frischer Daten, ist jedoch nicht dafür verantwortlich, bestimmte Datensätze in Ziel-Anwendungen zu transportieren, wie es eine herkömmliche Middleware tun würde.
- Darstellung eines Proxys für größere Datenmengen in der Cloud. Einige IoT-Architekten speichern in der Tat sehr große Datensätze im Digital Twin nativ und verschmelzen den Twin mit einer Data-Lake-Architektur. Dies ist zwar möglich, aber unserer Meinung nach nicht empfehlenswert. Wenn Sie große Mengen an Telematik- oder anderen Zeitreihendaten haben, sollten Sie vielleicht besser ein dediziertes Softwareprodukt oder einen Cloud Service dafür nutzen. Der Twin könnte automatisch Daten dorthin auslagern und immer noch einen Proxy für eine API anbieten. In diesem Fall wäre ein Entwickler in der Lage, immer (die API des) Digital Twin abzufragen, während dieser nativ nur für die aktuellsten Daten antwortet und die Anfrage für große Mengen älterer Daten weiterdelegiert.
- Einrichten eines Proxys für Echtzeitdaten auf dem Gerät. Das Digital-Twin-Konzept des Lesens und Schreibens auf Geräte, die gelegentlich offline sein können, lässt sich nicht auf alle Anwendungen übertragen. Manchmal müssen Sie sicherstellen, dass es sich bei den Daten um reale Echtzeitdaten handelt. Das nicht autonom gesteuerte Herausfahren eines Teslas aus einer Garage oder einem Parkplatz ist ein solches Beispiel. Andere Beispiele umfassen Daten mit Datenschutzbedenken, die nicht im Twin-Speicher des OEMs abgelegt werden sollten, sondern ausschließlich dem Eigentümer des Fahrzeugs zur Verfügung gestellt werden sollten.
Schauen wir uns die inoffizielle Tesla-API (www.teslaapi.io) an, die als Grundlage für alle Smartphone-Apps dient – sowohl für die offizielle Tesla-App als auch für viele Apps von Drittanbietern. Die API bildet den Zugang zu allen Tesla-Konsumerprodukten vollständig ab, einschließlich Autos und Heimbatterien oder Solarpanels. Entsprechend den obigen Richtlinien können wir die Datenbereiche klassifizieren und ihre externe Exposition untersuchen oder deren interne Nutzung durch Tesla annehmen. Wenn Unternehmens- und IoT-Architekten ein Datendomänen-Modell für einen Digital Twin entwickeln möchten, ist eine Aufteilung aller Entitäten in diese drei Klassen und durch zwei oder mehr Abstufungen der Privatspähre ein smarter Ansatz.
Dies sind die folgenden drei Datendomänen:
- Echter Digital Twin: In dieser Domäne werden der Remote-Zugriff und die Verteilung von Zuständen gemäß dem Konzept des Digital Twin ideal umgesetzt.
- Fernzugriff auf das Fahrzeug (Remote Vehicle Access): Dabei handelt es sich im Grunde um eine Proxy-API direkt zum Fahrzeug im Online-Zustand. Überraschenderweise fällt die Mehrheit der Consumer-APIs bei Tesla und die entsprechenden Datensätze in diese Kategorie.
- Fernzugriff auf die Cloud (Remote Cloud Access): Hierbei handelt es sich um eine Proxy-API für ein größeres in der Cloud gespeichertes Datenvolumen, wie oben empfohlen.
Der Unterschied zwischen echten Twin-Daten und der Domäne des Remote-Zugriffs auf das Fahrzeug wird im Falle von Tesla-Fahrzeugen sehr deutlich, da diese nach ein paar Stunden außer Betrieb in den Ruhezustand übergehen können. Während die grundlegenden Informationen über ein Fahrzeug und seinen Fahr-/Ruhezustand immer verfügbar sind, schlägt die Abfrage von Daten wie dem GPS-Standort fehl, wenn sich das Fahrzeug im Ruhezustand befindet. Der Entwickler der Anwendung muss die Wake-Up-API aufrufen und dann die GPS-Position erneut anfordern. Obwohl dies für die Entwickler ausgesprochen unbequem erscheint, ist der offensichtliche Hintergrund für die Lokalisierung dieser Daten in der Domäne „Fernzugriff auf das Fahrzeug“ die europäische Datenschutz-Grundverordnung. Wenn der Benutzer sein Fahrzeug nicht in den Online-Modus versetzt, hat Tesla keinen Zugang zu diesen privaten Informationen. Selbst wenn das Auto wie üblich online ist, speichert Tesla diese Informationen niemals in Verbindung mit der Identität des Fahrzeugs oder des Benutzers ab.
Die Verteilung der Daten über die Domänen sieht wie folgt aus:
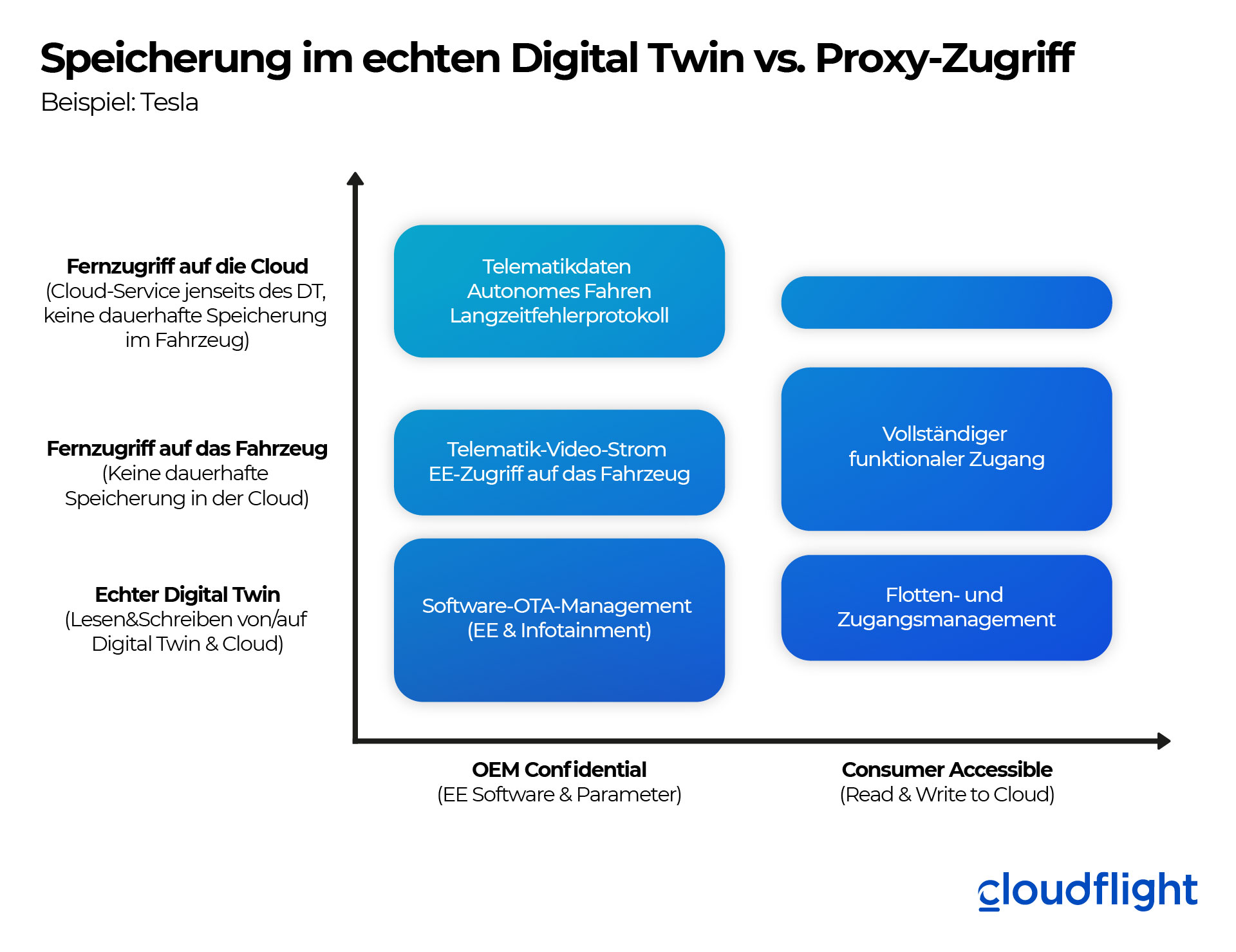
Zugriffsmethoden und Privatspähre von Teslas Digital Twin (Quelle: Cloudflight)
Zusätzlich zu den drei Zugangskategorien untersuchen wir zwei Privatsphäre, „OEM Confidential“ und „Consumer Access“. Die Größe der obigen Felder gibt die Anzahl der APIs und Datensätze oder Befehle für jede Kombination an. Wenn man einen Blick auf die für den Consumer zugänglichen APIs wirft, die auf www.teslaapi.io dokumentiert sind, ist es bemerkenswert, dass die meisten Daten tatsächlich NICHT im Digital Twin gespiegelt sind. Während dies für viele Experten für Datensicherheit und Datenschutz zweifellos eine gute Nachricht ist, bedeutet es gleichzeitig, dass für viele API-Aufrufe das gesamte Auto aus der Ferne aktiviert werden muss und dabei rasch ein Phantomstromverbrauch von mehr als 5 kWh pro Tag entstehen kann, während das Auto geparkt ist. Interessant ist auch, dass Tesla beschlossen hat, KEINE Cloud-Services über die historischen Daten des Autos offenzulegen. Wenn Sie also etwa ein vollständiges Batterieladeprotokoll erstellen möchten, müssen Sie z.B. eine Anwendung eines Drittanbieters verwenden oder Ihre Tesla API an ein Smart Home-System anschließen, das diese Daten problemlos protokollieren kann.
Es liegt auf der Hand, dass z.B. kommerzielle Fahrzeuge, wie gewerbliche LKW, die Datenbereiche völlig anders verteilen würden. Sobald sie eine vertrauenswürdige B2B-Beziehung mit dem Kunden hergestellt haben, werden so viele aktuelle Daten wie möglich im echten Twin gespeichert, um die Bandbreite und Latenzzeit des Remote-Zugriffs auf das Fahrzeug zu reduzieren. Darüber hinaus könnten kommerzielle Fahrzeuge historische Daten des echten digitalen Zwillings nutzen und daraus per Remote-Zugriff über die Cloud ein Geschäftsmodell entwickeln. Denken Sie an logistische Routenoptimierung oder ähnliche Anwendungsfälle.
Leider gibt Tesla nicht viel über die nicht-öffentlichen APIs und Datendomänen auf der linken Seite des obigen Bildes preis. Glücklicherweise ist es nicht schwer, die Kategorie „OEM Confidential“ auf der Grundlage öffentlich einsehbarer Merkmale zu analysieren:
- Echter Digital Twin & OEM Confidential: Alle OTA-Updates (Over-The-Air) von Software fallen in diese Kategorie. Tesla weiß genau, welche Softwareversion sich in jedem der mehr als 50 embedded Controller jedes Autos befindet – und das wissen sie mit Sicherheit ohne die Autos abzufragen.
- Fernzugriff auf das Fahrzeug & OEM Confidential: Tesla „zeichnet“ standardmäßig nur sehr wenige Daten auf. Aus Schadenersatzgründen erfassen sie zum Beispiel das autonome Fahreinstellungen im Falle eines Unfalls. Selbst wenn das Auto völlig zerstört und ohne Stromversorgung ist, erklärten sie in der Öffentlichkeit in einigen Fällen, dass bestimmte Autos zum Zeitpunkt eines Unfalls autonom fuhren oder nicht. Tesla zeichnet nur Telematikdaten auf, um das autonome Fahrverhalten zu verbessern, wenn der Benutzer die Datenfreigabe aktiviert. Tesla könnte für Diagnosezwecke auch Fernzugriff auf eingebettete Geräte erhalten – dies dürfte allerdings je nach Region unterschiedlich geregelt sein.
- Echter Zugriff auf die Cloud & OEM Confidential: Es gibt Beispiele, die belegen, dass bestimmte Fahrzeuge Zugang zu den von anderen generierten Daten erhalten. Die Lerndaten für die autonomen Systeme sind dabei das offensichtlichste Beispiel. Diese werden durch die Bereitstellung von Daten durch alle, die den Austausch von Telematikdaten aktiviert haben, verbessert. Ein weiteres Beispiel für diese Kategorie ist die Erfassung von Unebenheiten und Schlaglöchern auf der Straße. Sobald ein einzelnes Auto die im Federungssystem gemessene starke Vertikalbeschleunigung meldet, erhalten die folgenden Tesla Model S eine Warnmeldung, dass die Geschwindigkeit reduziert oder sie erhöhen die Bodenfreiheit mit der Luftfederung automatisch automatisch. Tesla behauptet offiziell, dass all diese Daten vollständig anonymisiert sind.
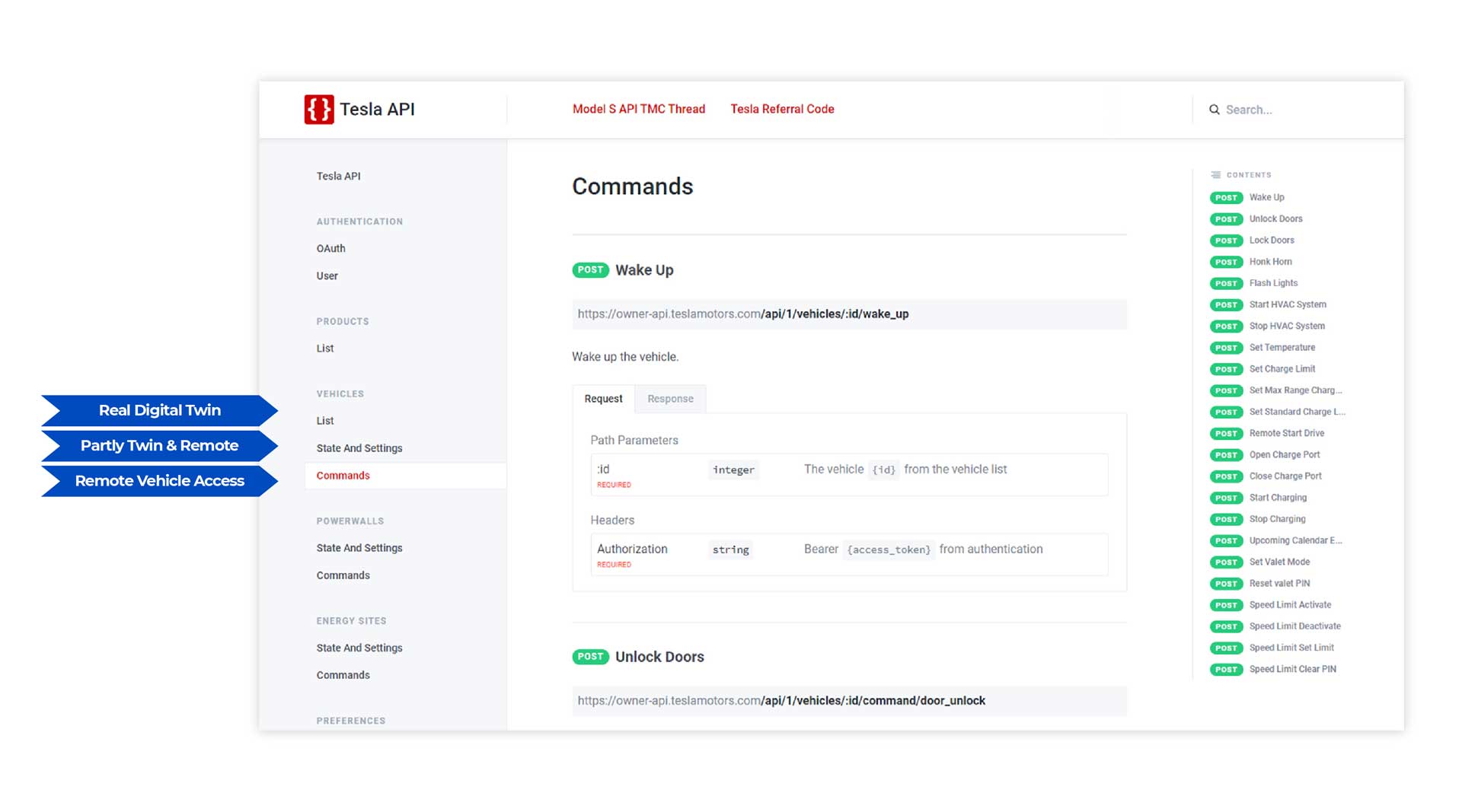
Tesla Digital Twin APIs: Quelle www.teslaapi.io
Tesla Digital Twin APIs: Source www.teslaapi.io (caption)Auf dem Bild ist die Tesla API-Dokumentation zu sehen und wie die Bereiche gemäß unserer Klassifizierung eingeordnet werden. Unternehmens- und IoT-Architekten sollten einen Blick auf diese Beispiele werfen und die eingeführten Datenkategorien des Digital Twin verwenden, um ihre Datenmodelle und Zugriffsschichten zu strukturieren. Der Ansatz trägt auch dazu bei, die Implementierungsphasen Ihrer individuellen Twin-Architektur flexibel zu strukturieren. Je nach digitalem Geschäftsmodell können Sie zunächst mit den Kategorien „OEM Confidential“ oder „Consumer Access“ beginnen.
Cloudflight stellt Ihnen auf Anfrage gerne weitere erfolgreiche Designbeispiele für den Digital Twin zur Verfügung.