- Datenanalyse ist die wichtigste Disziplin im digitalen Zeitalter
- Unterschiedliche Betriebs- und Deployment-Szenarien ermöglichen die Umsetzung von erfolgreichen Use Cases
- Stackology und Hadoop sind beide für den Einsatz und die Erfüllung geeignet
- Die Wahl der Strategie muss zur jeweiligen Unternehmenskultur und den Geschäftsmodellen entsprechend ausgewählt werden
<!–more–>
Datengetriebene Geschäftsmodelle sind für digitale Unternehmen ein wichtiges Standbein. Ohne die Daten über Produkte, Kunden, Lieferanten etc. sind die führenden Unternehmen von heute, bereits morgen ausrollend auf dem Abstellgleis anzutreffen. Damit Unternehmen hier nicht ins Abseits geraten, muss frühzeitig Initiative ergriffen werden. Data Analytics ist dabei eine wichtige Eigenschaft einer Unternehmens-DNA, die mit der Demokratisierung von Daten einhergeht – denn Daten sind das Produkt.
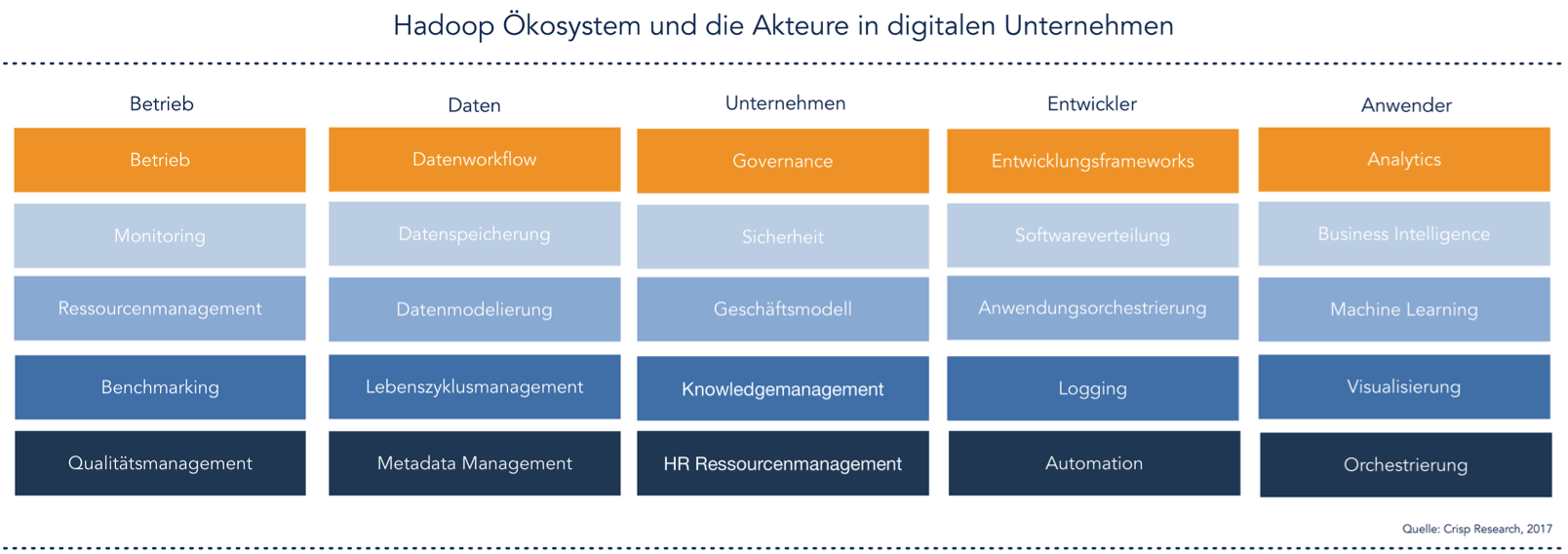
Hadoop Ökosystem entwickelt sich stetig weiter
Bereits im Jahr 2008 erblickte Hadoop das Licht der Welt. Doug Cutting war der Vater, der mit seinem Team bei Yahoo! damals die entsprechende Leistung vollbrachte, Data mit sehr vielen Maschinen in viel kürzerer Zeit analysieren zu lassen. Seitdem ist viel Zeit vergangen und die Hersteller, Anwender und die Open Source Community haben viel Energie in die aufkeimende Technologie gesteckt. Bis heute hat sich daraus ein stetig wandelndes System entwickelt, welches die Anforderungen innerhalb von allen Unternehmen mittlerweile erfüllen kann. Denn die Integration in eine Unternehmenslandschaft, war nicht von Anfang an gegeben. Viele sicherheitsrelevante und Governance und Compliance betreffende Tools mussten erst noch geschaffen bzw. implementiert werden. Über die Jahre hat sich so ein System entwickelt, welches viele Anforderungen von Unternehmen mit Hilfe unterschiedlichster Technologien abbilden kann. Die unterschiedlichen Akteure haben sich dabei im Kontext der Digitalisierung ebenso heraus entwickelt. Somit bietet ein Hadoop-System innerhalb des eigenen Rechenzentrums und/oder in der Cloud einen guten Startpunkt für die Erstellung neuer digitaler Geschäftsmodelle.
Stack, Stack und Stack – der Zoo im Rechenzentrum wächst
Stacks sind momentan der Renner in der Architektur von IT- und Applikationslandschaften. Technologiestacks, Architekturstacks, BigData-Stacks, IoT-Stacks, etc. Überall laufen einem diese Stacks über den Weg und es prägt sich der Begriff der Stackology. Sie sind damit der Gegenpol zu großen Hadoop-Installationen. Denn wie man bei Vertretern, wie dem IoT-Stack beispielsweise vermuten kann, sind viele bereits auf gezielte Anwendungsszenarien zugeschnitten. Für echtzeitnahe datengebundene Anwendungen beispielsweise gibt es entsprechend unterschiedliche Stacks, bei denen die Akronyme der verwendeten Tools – oftmals aus dem Open Source Bereich, den Namen bestimmen. SMACK ist einer dieser Stacks, der mit Apache Spark, Apache Mesos, Akka, Apache Cassandra und Apache Kafka für skalierbare Echtzeitanalysen konzipiert wurde. Für die gezielte Analyse von Zeitreihendaten im IoT-Zeitalter gibt es beispielsweise den TICK Stack (Telegraf, InfluxDB, Chronograf, Kapacitor). So können sich Unternehmen je nach Anwendungsszenario die entsprechenden Stacks innerhalb des Unternehmens aufbauen und zielgerichtet einsetzen. So setzen sich dann die Data Stacks aus unterschiedlichen “Silos” zusammen, die dann jeweils unterschiedliche Anwendungsfälle adressieren, wie z.B.:
- Batchverarbeitung
- Streaming-Datenverarbeitung
- Zeitreihenanalyse
- Business Intelligence
- Predictive Maintenance
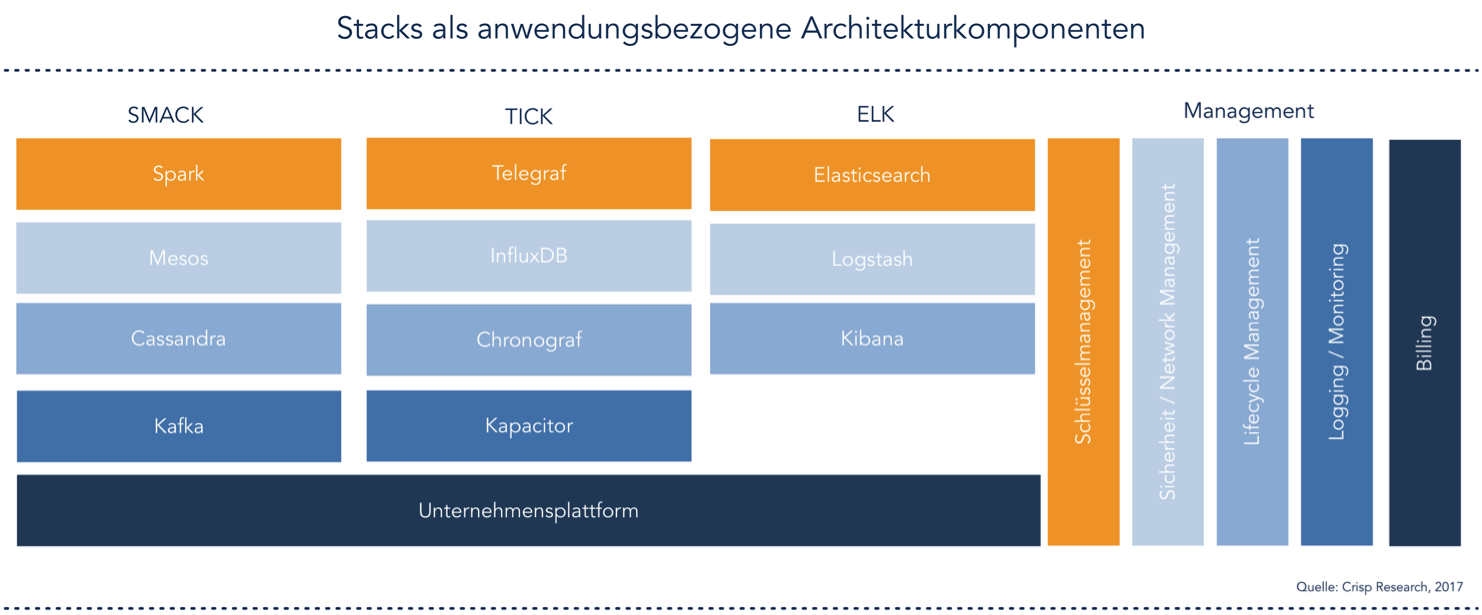
Für den CIO und den RZ-Leiter ergibt sich damit die Frage, wie und ob all diese Stacks denn tatsächlich in das eigene Rechenzentrum einziehen sollen und müssen, denn die Verwaltung und Wartung dieser vielen unterschiedlichen und zum Teil heterogenen Stacks ist sicherlich kein Zuckerschlecken. Alle Stacks müssen entsprechend sicher und performant bereitgestellt werden und der Betrieb und die Wartung möglichst einheitlich abgebildet werden.
Auch im Hadoop-Umfeld ist die Cloud gesetzt
Hybrid- und Multi-Cloud Modelle stehen bei den Unternehmen momentan hoch im Kurs. Und auch auf Seite der Anbieter gibt es zunehmend mehr Support und Integration aus, in und mit der Cloud. So bietet die kürzlich erschienene Version 2.8 von Hadoop viele Updates und Neuerungen im Bereich Cloud und Sicherheit. Darunter finden sich beispielsweise die Unterstützung bzw. optimierte Unterstützung von Microsoft und AWS Object Storage Angeboten zur Nutzung als Data Lake. Und auch die strömenden Unternehmensdaten können zunehmend hybrid analysiert werden. So stellte beispielsweise Hortonworks gerade die Version 3.0 seiner Open-Source-Data-in-Motion-Plattform Hortonworks DataFlow (HDF) vor, mit der genau dies möglich ist.
Welche Strategie kommt in Frage?
Für Unternehmen gibt es keine generelle Antwort auf diese Fragestellung. Denn jedes Unternehmen hat eine andere Strategie für die digitale Welt. Je nachdem, wie Daten analysiert und eingesetzt werden, kann die eine oder andere Strategie effizienter und kostenbewusster sein. Denn für die Umsetzung von Szenarien, in denen nur fließende Daten analysiert werden sollen und darauf reagiert werden soll, kann die Nutzung von Stacks sinnvoller sein. Sind viele große Business Units mit unterschiedlichen Anforderungen und Fragestellungen an einer Datenanalyse interessiert, dann rechnet sich sicherlich die Investition in Hadoop-Installationen im On-Premise oder Cloud-Umfeld. Die Handlungsempfehlungen sind demnach:
- Anwendungsfelder scannen
- Anforderungen bestimmen
- Business Units / Fachabteilungen und IT mit ins Boot holen
- Bedarf kalkulieren
- Auswahl treffen



