
Edge Computing geistert schon seit mehr als drei Jahren durch die Technologie-Szene und ist immer noch ein unscharf definierter Begriff. Genauso wie in den Anfängen des Cloud-Computings, liegt dies daran, dass verschiedene Hersteller versuchen den Modebegriff genau für ihre bereits vorhandenen Produkte zu nutzen. In den Anfängen des Cloud-Computing nannten wir Analysten das “Cloud-Washing”. Heute erleben wir fast das gleiche wieder mit den Edge Computing-Anbietern. Aber auch die CIOs sollten sich selber nichts vormachen. Genauso wie noch lange nicht jedes Enterprise-Rechenzentrum zu einer Private Cloud wird, wird auch nicht aus jedem lokal verteilten Computer oder IoT Device eine Edge Computing-Topologie. Dieser Expert View ist deshalb nicht nur für die Anbieter der neuen Computing-Klasse essentiell, sondern auch für CIOs, die wirklich die Vorteile verstehen und nutzen möchten, ohne dabei auf das Marketing globaler und lokaler Anbieter hereinzufallen. Der Expert View ist der erste einer kleinen Serie von drei Artikeln zu denen es auch ein freies Webinar gibt.
Leider hat sich die Industrie auf keine oder nur eine sehr allgemeine Definition geeinigt. Das kommt dabei heraus, wenn jeder Hersteller seine Technologie in dem Begriff sehen will:
Edge Computing ist jede Art von Rechen-, Speicher oder Netzwerk-Leistung, die sehr nahe an einem Nutzer oder an einer Maschine und weit weg von konsolidierten Rechenzentren ist. (Edge Computing Definition Wikipedia)
Danach wäre jeder PC, der auf einem Arbeitsplatz und nicht in einem Rechenzentrum steht, ein Edge Computing Device. Cloudflight sieht jedoch sowohl das Device in der Netztopologie als auch das Computing-Paradigma als Charakteristika für Edge Computing.
Edge Computing ist ein Computing-Ansatz bei dem an vielen dezentralen Stellen einer größeren Netzwerk-Topologie Rechen-, Speicher-, oder Netzwerkleistung in gleicher Art und Weise zur Verfügung gestellt wird, teilweise autonom agieren kann, aber zentral gemanagt wird. (Edge Computing Definition Cloudflight)
Bei dieser Definition wird klar, dass nicht jeder dezentrale PC oder jedes Internet-Gateway an einer Industriemaschine zum Edge Computing wird. Im Einzelnen sprechen wir von Edge Computing, wenn diese Charakteristika gegeben sind:
- Edge-Topologie: Ein einzelner Computer oder ein Embedded Device ist erst dann ein Edge Computing Device, wenn es eben am Rand einer größeren Netzwerktopologie ist. Dabei ist es nicht entscheidend ob ein Edge-Device direkt mit einer Public oder Private Cloud oder einem nächstgrößeren Edge-Device – oder sogar mit allen gleichzeitig kommuniziert. Es muss nur eben überhaupt eine Konnektivität haben. Sogar, wenn diese nur sporadisch gegeben ist, ist doch die Weitergabe von Daten bis hin zur real-time Interaktion einer der beiden wichtigsten Aufgaben eines Edge Computing Ansatzes.
- Edge-Rechen-, -Speicher- oder -Netzwerkleistungen: Neben der Kommunikation mit dem Rest der Netzwerk-Topologie, ist die lokale Autonomie
die zweite wichtige Eigenschaft von Edge Computing. Eine Robotersteuerung muss lokal Menschen erkennen und ggf. Bewegungen verlangsamen um Unfälle zu verhindern, aber auch gleichzeitig in einen größeren Industrie 4.0 Verbund integriert werden. Oder eine Ampelsteuerung an einer Großstadt-Kreuzung muss 100%ig zuverlässig und konsistent funktionieren um ein lokales Verkehrschaos zu vermeiden, gleichzeitig aber – wenn möglich – mit umliegenden Ampeln oder einer Verkehrsleitzentrale kommunizieren um Staus und Emission zu reduzieren.
- Edge-Device Klasse: Obwohl Edge Computing eine sehr große Bandbreite von Devices einschließen kann, reden wir doch nur von Edge Computing, wenn mindestens ein non-Constrained-Controller vorliegt, der beispielsweise schon ein Dateisystem hat, in dem kundenspezifische Programme oder Daten gespeichert werden. Am oberen Ende können durchaus leistungsfähige Rechner liegen, wie man sie heute in autonomen Fahrzeugen oder in automatisierten Fabrik-Hallen braucht. Solange diese selbst wiederum “äußerer” Teil einer zentralen Topologie sind, kann man sehr wohl von Edge Computing sprechen. Klassische Enterprise-Computing Server, die sehr individuell mit Unternehmenssoftware beladen sind, stehen aber gerade deshalb in klassischen Rechenzentren on-premises, weil sie nicht zu einem noch zentraleren Knoten (außerhalb des Unternehmens) kommunizieren sollen. Diese Compute-Ressourcen bezeichnen wir deshalb klar nicht mehr als Edge Computing.
- Standardisiertes Deployment und Management auf die Edge: Eine einzelne virtuelle Maschine oder ein Container ist noch lange keine Cloud Computing Plattform. Erst hohe Standardisierung, Automatisierung und letztlich das flexible Pay-Per-Use Abrechnungsmodell erzeugen eine Public oder Private Cloud. Genauso ist es beim Edge Computing: Dezentral verteilte Rechenleistung ist noch lange kein Edge Computing Ansatz. Deshalb bezeichnen wir beispielsweise traditionelle SCADA Systeme (Supervisory Control and Data Acquisition), wie sie an unzähligen Industrie-Anlagen im Einsatz sind, nicht als Edge Computing. Ihre Software wird meist einmalig bei der Inbetriebnahme der physischen Anlage ausgeliefert und danach kaum und erst recht nicht automatisch und zentral aktualisiert. Jede Maschine kann einen anderen Softwarestand haben. Auch sprechen die klassischen SCADA-Systeme – vor allem aus Sicherheitsgründen – nicht mit anderen Teilen einer Netzwerktopologie. In der Praxis wird ein SCADA System dann oft mit einem kleinen lokalen Internet-Gateway ergänzt, das genau die entgegengesetzten Eigenschaften des SCADA selbst hat, also hoch standardisiert ist, aus der Ferne gemanagt wird und Sensor-Daten weitergeben kann. Solche Retro-Fit Gateways bezeichnen wir deshalb als Edge Computing Device.
Damit hängt die Definition von Edge Computing eben nicht nur von der Größe und den Eigenschaften eines Devices, sondern von dem größeren Konzept ab, in dem diese Devices agieren. Vergleichen wir es mit dem Client/Server-Computing: Hier wurde auch nicht jeder PC automatisch zum Client einer Client/Server-Topologie. Viele PCs waren einfach etwas bessere Schreibmaschinen und agierten vollkommen lokal. Nur die PCs, die mit identischen oder zumindest kompatibler Client-Software beladen waren, konnten mit der Server-Software im Rechenzentrum agieren.
Würde man Edge- und Client/Server Computing mit der Natur vergleichen, wäre es wahrscheinlich ein Baum mit vielen Blättern und Wurzelenden. Während die Blätter für Menschen sichtbar sind, wie heute Clients oder mächtige Browser-Anwendungen wie Google’s GSuite, symbolisieren die Wurzeln viele unsichtbare Edge Computing Devices, von der Wurzelspitze, über kleinere und mittlere Knoten, bis zu dem Baumstamm, der beide Teile in einem Corporate Network zusammenbringt. Schauen wir uns die verschiedenen Edge Computing Device-Klassen und ihren üblichen Platz in der Topologie etwas genauer an: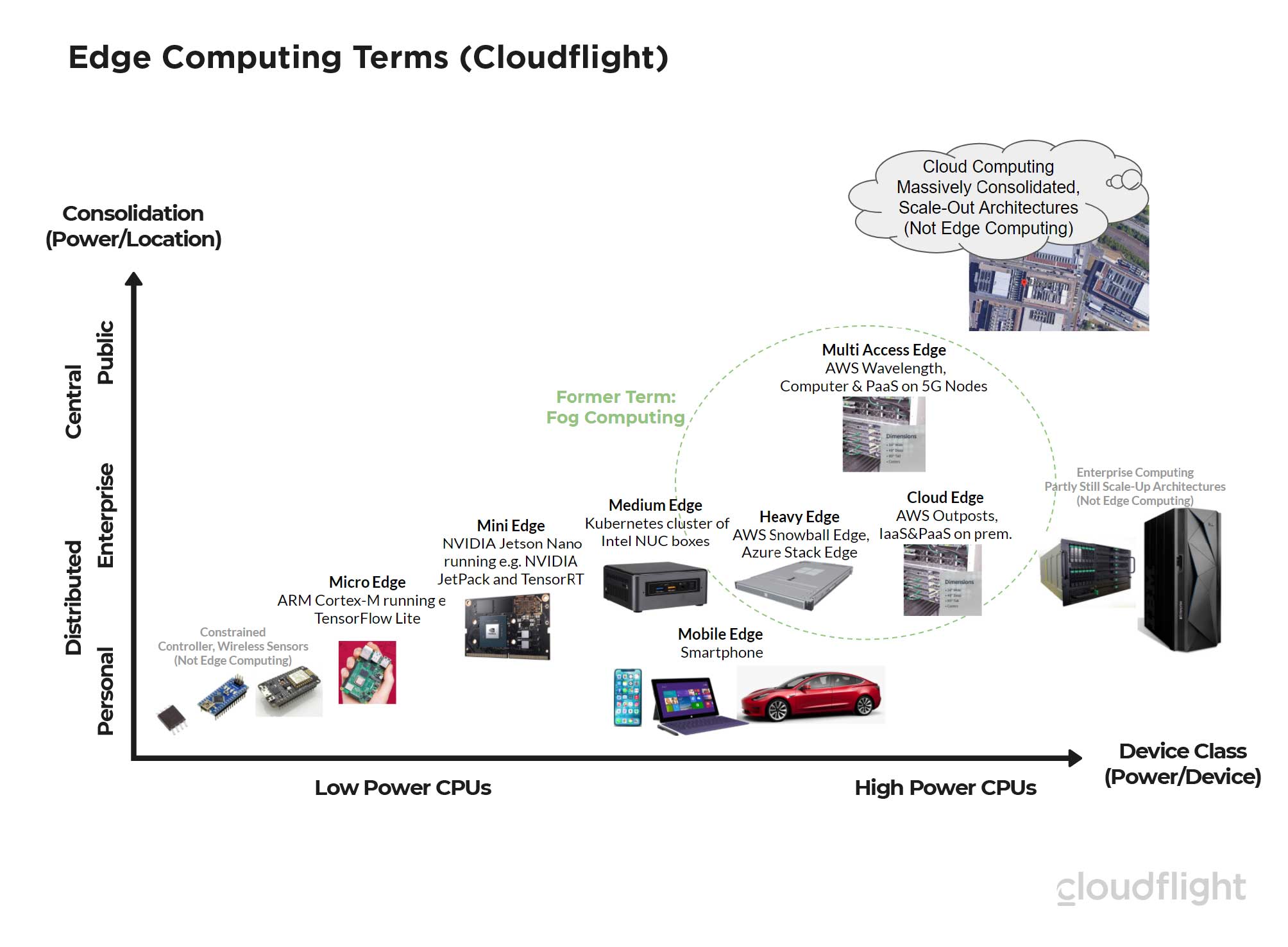 Das Bild zeigt nach oben die zentrale Konsolidierung und entsprechend nach unten die dezentrale Verteilung von Devices nah zu Menschen oder Maschinen und eben weit weg von einer zentralen Rechenzentrums-Infrastruktur. Von links nach rechts sind die Leistungsklassen aufgetragen. Im Einzelnen sieht man folgende Gruppen:
Das Bild zeigt nach oben die zentrale Konsolidierung und entsprechend nach unten die dezentrale Verteilung von Devices nah zu Menschen oder Maschinen und eben weit weg von einer zentralen Rechenzentrums-Infrastruktur. Von links nach rechts sind die Leistungsklassen aufgetragen. Im Einzelnen sieht man folgende Gruppen:
- Constrained Controller – noch kein Edge Computing. Ganz links sind kleine Micro-Controller in der Leistungsklasse Milliwatt bis ca. 1 Watt. Man findet die kleineren Vertreter beispielsweise mit einem ATMEL ATTINY oder einem Espressif EPS32 Controller heute in Lichtschaltern, Rauchmeldern mit Standby-Strömen von ca. 1µA. Eine Batterie hält also 5 Jahre oder länger. Die etwas größeren Constrained Controller können durchaus schon lokale Aufgaben beispielsweise in Fahrzeugen autonom übernehmen. Weil es aber weder ein echtes Dateisystem, noch genügend Rechen-, Speicher- oder Netzwerkleistung gibt, bezeichnet man diese kleinen Controller noch nicht als Edge Computing Devices.
- Micro-Edge – die kleinen Linux Devices. In dieser Leistungsklasse zwischen einem halben und vier Watt pro Controller kann man schon ein gehärtetes Linux-System darstellen und hat kaum noch klassische Einschränkungen (Constraints) der kleinen Mikrocontroller. Hier ist auch der für Prototypen beliebte Raspberry Pi angesiedelt. Kommerzielle Hersteller wie Wago oder INSYS icom bieten auf ihren Mini-Industrie-Rechnern für den Einbau in Schaltschränke inzwischen auch die Möglichkeit kundenspezifische Software als Docker-Container zu deployen. Damit hat man einerseits ein extrem stabiles und andererseits auch ein sehr flexibles System. Hier laufen auch schon Machine-Learning Frameworks wie das TensorFlow Lite.
- Mini-Edge – mehr Leistung für spezielle Anwendungen. Hier sind zum Beispiel spezielle Edge-Machine-Learning Devices wie das NVIDIA Jetson Nano auf dem das deutlich stärkere Nvidia TensorRT läuft. In der benötigten Leistung sind diese Devices etwas höher, aber können immer noch extrem verteilt sein. Besonders die Machine Learning Anwendungen machen hier fast nur Sinn, wenn die lokale Autonomie fortlaufend mit einem Lernprozess in der Cloud verbunden ist. Damit sind personenbezogene oder vertrauliche Daten lokal, aber die größere künstliche Intelligenz entsteht auf einem großen Pool anonymisierter Daten in der Cloud.
- Medium Edge – die Industrie PCs oder Kubernetes Knoten. Hier reden wir von 5 bis 25Watt Leistungsverbrauch pro Device. Logischerweise sind diese Devices schon zu groß um sie in einen Lichtschalter einzubauen. Meist konsolidieren sie eine ganze Fertigungsmaschine oder eine ganze Etage oder gar ein ganzes Gebäude in der Gebäudetechnik. Hier kann man schon deutlich größere Rechenaufgaben dezentralisieren. Besonders interessant ist das Management von Containern mit Kubernetes. Die Medium Edge Devices erscheinen dort genauso wie ein Compute Node in der Cloud. Es macht also gar keinen Unterschied ob ein Container ganz alleine in der Edge landet, oder zusammen mit 20 anderen Containern auf einer virtuellen Maschine, die zusammen mit 10.000 anderen VMs in einem Rechenzentrum an einem Ort sind.
- Heavy Edge – verteilte Server für spezielle Aufgaben. Inzwischen gibt es praktisch für jede Leistungsklasse Rechnersysteme. Fallen beispielsweise an einer Fertigungsanlage Daten im Bereich von Terabyte pro Tag oder mehr an, macht es aus Latenz- und Kostengründen wenig Sinn dies alles in eine Cloud oder auch in ein Corporate Data Center außerhalb des Fertigungsstandortes zu transportieren. In vielen Fällen braucht man diese Daten auch nur eine bestimmte Zeit lang aus Compliance-Gründen oder kann sie löschen nachdem sie von Lern- und Analytics-Algorithmen verarbeitet wurden. Hier helfen Heavy Edge Systeme die meistens nur Teile eines Racks ausfüllen, aber neben Enterprise Infrastruktur-Anbietern auch von den Public Cloud Providern angeboten werden (z.B. AWS Snowball Edge, Azure Stack Edge). Die Heavy Edges beschränken sich meist auf einzelne Aufgaben wie die Datenspeicherung und sind nur teilweise in die Management-Systeme der Public Clouds eingebunden.
- Cloud Edge – ein Stück Public Cloud im Unternehmen. Nachdem die Public Cloud Provider jahrelang eben nur Dienste in der Cloud bereitstellen konnten, wurde der Bedarf hybrider Ansätze inzwischen von allen drei Hyperscalern (AWS, Google, Microsoft) mit entsprechenden Cloud Edge Angeboten adressiert. Ganz entscheidend zur Charakterisierung einer Cloud Edge ist es, dass diese eben nicht nur Infrastruktur-Dienste (IaaS) sind, sondern der Provider große Teile seiner Plattform-Software-Dienste (PaaS) auch als fully-managed Service auf Hardware bei Kunden bringt. Beispiel sind hier vor allem Microsofts Azure Stack, die lokale Hardware mit ihren Partnerunternehmen darstellen und Amazons AWS Outposts, die es mit eigener Hardware darstellen. Eine genauere Analyse der Cloud-Edge Angebote der Hyperscaler lesen Sie gerne in diesem Expert View. Zwischenzeitlich gibt es auch lokale Cloud Provider in Deutschland, die neben lokalen Rechenzentren auch Cloud-Edge Lösungen anbieten, die Plattform-Software für die Fertigungsindustrie enthalten. Die Oncite ist ein Beispiel hinter dem die German Edge Cloud steht (in der auch die Innovocloud aufgegangen ist) sowie die Firmen IOTOS und BOSCH. Insbesondere die Nutzung des Gaia-X Frameworks auf einer Cloud-Edge und parallel auf mehreren Public Clouds ist sehr erfolgversprechend für die Industrie 4.0 Szenarien (siehe dazu die Cloudflight Analyse von Gaia-X).
- Mobile Edge – nicht jedes Auto ist Edge Computing. In der Leistungsfähigkeit reihen sich natürlich von links nach rechts auf der Abbildung auch die Mobile Devices vom Smartphone, über Laptops bis zu modernen Autos ein. Sie sind sehr nah an den Nutzenden und damit potentiell sehr weit weg in der Topologie zu zentralen Infrastrukturen. Wenden wir wieder die oben genannten Kriterien für Edge Computing an, kann man beispielsweise nur diese Fahrzeuge als Edge Computing Devices bezeichnen, die in regelmäßigem Austausch in Bezug auf Daten und lokal ausgeführte Programme mit einer zentralen Infrastruktur stehen. Üblicherweise kommunizieren diese modernen Fahrzeuge dann mit einem Digitalen Zwilling über den wiederum andere Prozesse oder Mobil-Apps mit dem Fahrzeug interagieren (siehe dazu den Cloudflight Expert View zu digitalen Zwillingen). Ein traditionelles Fahrzeug, dass eben nicht Teil einer größeren Netzwerk-Topologie ist, würden wir eher nicht als Edge Computing bezeichnen, entsprechend zu den traditionellen SCADA Systemen an Industrieanlagen.
- Multi Access Edge – Rechenleistung in 5G Knoten. Während die Cloud Edge wirklich in einem einzelnen Unternehmen steht und nur von ihm genutzt wird, kann man genau den gleichen Ansatz auch in die “Telco-Edge” stellen. Damit meinen Telekommunikations-Provider Lokationen, die sehr weit draußen auf dem Weg zu Sendeanlagen und eben nicht in konsolidierten Rechenzentren sind. In diesem Fall wird die Infrastruktur natürlich gemeinsam von vielen Kunden genutzt. Diese Ansätze sind besonders für Software-Anbieter im SaaS-Modell attraktiv. Während zentrale Applikations-Teile beispielsweise aus AWS in der Public Cloud betrieben werden, können latenzkritische Teile wie beispielsweise eine Video-Relay-Software direkt in der “Nähe” der Anwender provisioniert werden. Kommt die Multi Access Edge vom gleichen Provider (AWS Wavelength) kann sie aus dem gleichen Cloud Management System provisioniert werden. Technisch erscheinen die Multi Access Edges einfach als weitere Availability Zones. Passiert diese Provisionierung auch noch automatisiert, spricht man von Network Function Virtualisierung (NFV) auf der Edge.
- Enterprise und Cloud Computing – beides zentrale Ansätze. Cloud Rechenzentren bewegen sich inzwischen für einzelne Availability Zones im Bereich von 100 Megawatt. Damit sind sie deutlich stärker konsolidiert als die meisten großen Enterprise Data Centers. Dennoch verfolgt die Cloud-Infrastruktur einen Scale-Out Ansatz, der gut zu Cloud-Native Architekturen passt. Hier finden sich eine große Zahl von gleichen vornehmlich mittelgroßen Servereinheiten. Im Gegensatz dazu gibt es immer noch viel Unternehmenssoftware, die mit wachsender Unternehmensgröße immer größere Server bis hin zu großen SAP Hana Shared Memory Appliances oder Mainframes reichen. Der Mainframe ist also noch weiter rechts auf der Abbildung als das Public Cloud Rechenzentrum, dieses ist aber viel größer konsolidiert und deshalb am weitesten oben.
Trotz der langen Liste ist der Markt immer noch in Bewegung. Es ist absehbar, dass neue Edge-Kategorien auftauchen oder andere wieder verschwinden. So sprachen auch einige Hersteller bei den leistungsfähigen Edge Computing Gruppen in Unternehmen und auf der Telco-Edge von Fog-Computing. Der Begriff findet aber heute kaum noch Anwendung in Europa.
Wie bereits oben angesprochen, ist die Software-Architektur und die Netzwerktopologie ein wichtiges Merkmal von Edge Computing. Die Summe aus Infrastruktur, Topologie und Software-Architektur bezeichnen wir als Computing Konzept oder Paradigma. Um CIOs die Identifikation von Edge Computing Opportunities einfach zu machen, haben wir die Charakteristika der vier gängigen Computing-Paradigmen verglichen: In der Abbildung werden neun Charakteristika von Computing Paradigmen betrachtet und farblich dargestellt wie stark oder schwach sie zutreffen. Eine vollständige Diskussion der neun mal vier, also 36 Ausprägungen würde sicher den Rahmen dieses Expert Views sprengen. Wir beschränken uns deshalb auf einig Beispiele oder die bemerkenswerten Charakteristika:
In der Abbildung werden neun Charakteristika von Computing Paradigmen betrachtet und farblich dargestellt wie stark oder schwach sie zutreffen. Eine vollständige Diskussion der neun mal vier, also 36 Ausprägungen würde sicher den Rahmen dieses Expert Views sprengen. Wir beschränken uns deshalb auf einig Beispiele oder die bemerkenswerten Charakteristika:
- Zentrale Rechenleistung ist bei Edge Computing kaum nötig. Die Edge ist ja selbst autonom unterwegs. Um eine Edge Topologie zu betreiben ist erst einmal keine zentrale Leistung nötig wie beim Client-Server-Ansatz. Die Anforderungen an die zentralen Management Systeme sind gering. Dennoch kombinieren viele Software Architekturen – besonders um Machine Learning – die Edge, die überhaupt mit meist sparsamen Rechnern auskommt, mit dem Cloud Computing, das große Leistung an zentraler Stelle zur Verfügung stellt.
- Minimale Latenz ist ein großer Vorteil von Edge Computing. Auch die schnellsten Netzwerkanbindungen einer industriellen Fertigung in eine Public Cloud haben heute 10 bis 20 Millisekunden Latenz. Die Edge, sehr lokal, kann beispielsweise Roboter im Mikrosekunden Bereich steuern.
- Um so größer die Edge, um so höher verfügbar ist sie meistens. Public Clouds sind – wenn man sie richtig nutzt – durch redundante Availability Zones und persistente Business-Daten an wenigen Stellen des Software Stacks sehr hoch verfügbar. Zudem helfen Kubernetes und Terraform Multi-Cloud Deployments zu realisieren. Applikationen können also in Minuten bei einem anderen Provider entstehen, falls wirklich überregional ein ganzer Public Cloud Provider ausfällt. Diese Multi-Cloud Strategien erreichen im Moment die allerhöchsten Verfügbarkeiten (siehe Spalte Reliability). Die Cloud Edge und auch viele Heavy Edge erreichen zumindest eine mittlere Verfügbarkeit wie klassisches Enterprise Computing On-Premises. Die kleineren Edge-Klassen sind aber einzelne Devices, die meist keine hochverfügbare Strom- oder Netzwerkversorgung haben. Damit haben einzelne Edge Devices alleine eine schlechte Reliability.
- Code-Portability – Ein alter Traum wird Realität. Seitdem es Betriebssysteme gibt träumt man davon Code, der auf einem System geschrieben wurde, auch auf anderen Rechnern laufen zu lassen. Die Kombination aus Container-Technologie und der über weite Bereiche standardisierten Intel Architektur ermöglichen es von dem Medium Edge bis in die Public Cloud exakt die gleichen Container auszuführen. Wenn man auf die Code-Ebene geht, die von mehreren Prozessor-Familien ausgeführt werden kann, wie beispielsweise AWS mit Greengrass auf der Edge und Lambda in der Cloud, kann man tatsächlich vom 4 Watt Raspberry bis zum 100 Megawatt Rechenzentrum den gleichen Code ohne Änderungen ausführen. Für die Mobile Edge geht das in der Praxis meist nicht.
Letztlich macht also die Software Architektur die Edge Computing-Topologie erst zu einem Edge Computing Paradigma, das sich in allen Bereichen von den bestehenden Computing Paradigmen abhebt. Damit können CIOs Marketing-Versprechen von Fakten unterscheiden und Edge Computing als realistischen Beitrag zur Infrastruktur von Morgen einplanen. Auf der strategischen Ebene sollten Sie für Ihre Infrastruktur-Planung folgendes mitnehmen:
Edge Computing Guidelines 2021:
- Edge Computing ist ein neues Computing-Paradigma.
- Edge und Cloud Computing koexistieren meistens und konkurrieren kaum.
- Sehen Sie ein zentrales Management der verteilten Infrastruktur vor.
- Edge Computing macht viele Industrie 4.0 Anwendungen durch niedrige Latenz erst möglich.
- Ein IoT Device alleine ist kein Edge Computing. Planen sie die Netztopologie.
- Edge Computing ist nur durch Standards interoperabel mit der Cloud und Enterprise Computing.
- Infrastruktur und Software Architektur gehören im Cloud-Native-Zeitalter eng zusammen. Mischen Sie die Teams im Unternehmen.
Diese Guidelines helfen hoffentlich sehr konkret bei der Infrastruktur- und Budgetplanung für Ihr erfolgreiches Jahr 2021.



